

With the rapid evolution of AI technology, data transmission rate and interconnection efficiency have increasingly become the key bottlenecks limiting the performance improvement of AI systems. Especially in the expansion of large model computing and data centers, high-bandwidth and low-latency accelerator interconnection solutions have become a strategic highland in the AI hardware ecosystem. Recently, the first high-speed interconnection chip that supports the UALink specification led by the UALink Consortium is about to enter the tape-out stage, which has attracted widespread attention in the industry. At the same time, NVIDIA continues to strengthen its leadership in AI connectivity with its next-generation NVLink Fusion. The confrontation between open ecology and closed platform is reshaping the industrial map of AI chip interconnection.
Ⅰ UALink: A new starting point for an open and connected ecosystem
According to a June 2024 report by Electronic Times, the UALink Consortium, jointly established by AMD, Broadcom, Google, HPE, Intel and Microsoft, plans to tape out the first high-speed interconnection chip that meets the UALink specification by the end of 2025. This marks the transition of the technology from the standard setting stage to the actual productization, and indicates that the first UALink-based servers and AI systems may be implemented in 2026.
Ultra Accelerator Link (UALink) is an open standard designed for AI and high-performance computing scenarios, with the goal of providing high-bandwidth and low-latency communication between accelerators, CPUs, and switches. Compared with traditional solutions such as PCIe, CCIX or NVLink, UALink emphasizes openness and scalability, enabling a wider range of collaboration between vendors. For example, UALink version 1.0 provides bidirectional transfer rates of up to 50GB/s per lane and supports interconnected configurations of up to 1024 accelerators, which is designed for the training needs of very large models.
This highly composable interconnection structure will provide more flexible topology deployment solutions for data centers, reduce vendors' dependence on single-vendor technologies, and provide a window for small and medium-sized vendors to enter the AI computing infrastructure market.
Ⅱ Compared with NVLink Fusion: openness against closure, the ecological pattern is undercurrent
1. Openness and ecological strategy
In terms of ecological strategy, UALink focuses on the "completely open" standard alliance model. Whether you're a processor vendor, a cloud service provider, or an independent hardware developer, you can design accelerators or connected devices based on UALink. This strategy is significantly different from NVIDIA's NVLink Fusion, which claims to be "partially open" to partners when it is released in 2024, but still requires at least one end to use NVIDIA-designed CPU or accelerator IP, and is still mainly a closed ecosystem.
This is especially evident in platform adaptation. UALink allows CPU and GPU manufacturers to freely combine, which is conducive to the formation of a multi-technology coexistence market pattern, while NVLink Fusion is more like an extension of the NVIDIA hardware stack (such as Grace CPU and Hopper GPU) to deep integration, with a stronger binding effect.
2. Performance and scalability
When it comes to raw performance metrics, NVIDIA NVLink maintains its lead. Its fifth-generation technology (for H100 and GH200 platforms) can achieve up to 1.8TB/s of bidirectional interconnection bandwidth with a single GPU, far exceeding PCIe 5.0 (about 64GB/s) and traditional CCIX interfaces, and is an important support for the high bandwidth requirements of AI training and inference tasks.
However, from a topology scaling perspective, UALink provides higher system-level connectivity. Its structure supports larger-scale device interconnection, and can theoretically support hundreds or even thousands of accelerator nodes for collaborative computing. In the design of computing architectures for next-generation multimodal large models, this ability to support large-scale clusters may become a key competitive point.
3. Ecological maturity and market dependence
NVIDIA has been deeply involved in the AI field for many years, and its CUDA software ecosystem is highly coupled with hardware platforms, so that NVLink technology is widely deployed in DGX systems, supercomputers, and multiple cloud vendor instances. This closed and mature system ecosystem greatly enhances NVIDIA's control over the AI hardware supply chain.
In contrast, UALink is still in the early stage of development, and although many giants participated, it still needs to go through the market verification of multiple links such as chip tape-out, motherboard verification, driver adaptation, and compiler optimization, and the completeness of ecological construction is not as complete as NVLink. However, in the long run, its strategic path of "platform neutrality + multi-vendor collaboration" is more conducive to lowering industry entry barriers and breaking the monopoly of a single vendor.
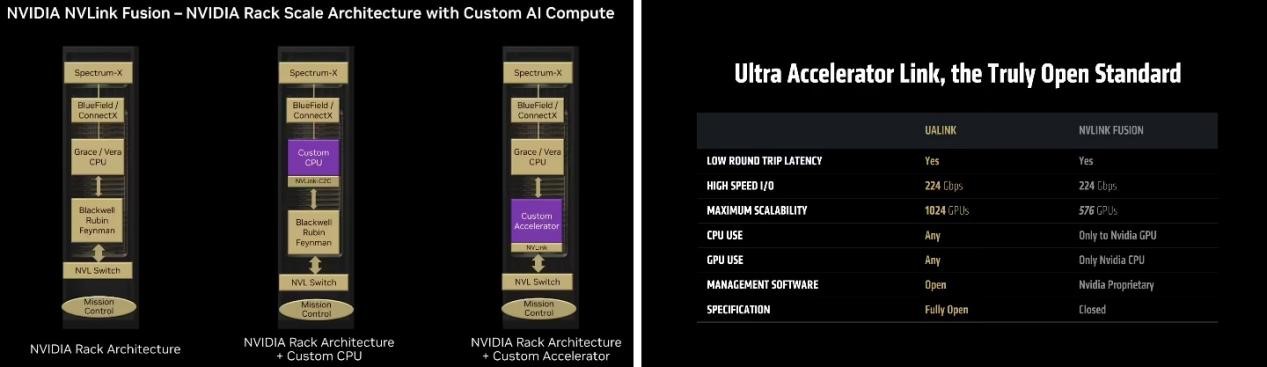
Figure: NVLink Fusion requires an NVIDIA CPU or ASIC, and the UALink ecosystem is open and has an advantage in the number of devices
Ⅲ Market outlook: Multi-faceted interconnection architecture is becoming a trend
From the perspective of the development path of the entire AI infrastructure, it is difficult for a single interconnection technology to meet the needs of all scenarios. Application scenarios such as AI training clusters, edge-side inference devices, and cloud accelerator services in data centers have different requirements for bandwidth, topology, and latency, which determines that multiple technical solutions will develop in parallel in the future.
If UALink can successfully tape out in 2025 and complete the server-side deployment verification, it is expected to start participating in a new round of bidding for AI cluster construction projects in 2026. In particular, driven by some non-NVIDIA companies (such as AMD, Intel, and Google Cloud), UALink may become an important underlying interconnection standard for building heterogeneous computing platforms.
At the same time, NVIDIA is not sitting still. The launch of NVLink Fusion, combined with its advantages in software ecology and AI model deployment, will continue to maintain a strong position in the high-end AI server market. It is expected that in the next few years, UALink and NVLink Fusion will compete differently in different segments: the former will focus on open and horizontal expansion capabilities, while the latter will dominate specific high-end markets with vertical integration and ecological closed-loop.
Ⅳ Challenges and key variables
Despite its potential advantages, UALink faces several real-world challenges:
* Long ecosystem build cycle: It still takes time to improve the software stack, driver support, motherboard design, testing and verification, etc.
* Uncertain market acceptance: There is still a question mark over whether large cloud vendors will be willing to migrate to UALink on top of their existing architectures.
* Caution is required in the evolution of technical standards: the subsequent introduction of 1.1/2.0 specifications needs to maintain compatibility and continuous performance improvement.
All of these require the UALink Alliance to further strengthen coordination in technology promotion, cooperation mechanisms and industry standard development.
Ⅴ Conclusion: Who can become the new overlord of AI interconnected infrastructure as the ecological changes begin?
The first UALink specification chip is about to be taped out, marking a new stage of multipolar competition for AI interconnection technology. This is not only a showdown of technical performance, but also a game of open and closed ecological paths. In the context of AI computing power becoming a national strategy and the core resource of enterprises, the restructuring of the pattern of interconnected chips is not only related to the competitive situation of chip manufacturers, but also affects the infrastructure layout of the global AI industry.
In the next few years, we will witness the formation of an important trend: the evolution of AI interconnection standards from "single dominance" to "multiple coopetition". Whether you choose NVIDIA's closed stack or invest in UALink's open alliance, you need to weigh the pros and cons of your business needs, development resources, and future compatibility to develop the most appropriate strategic roadmap.




